Hard: «Новая старая» архитектура Core i7: чего больше — сходства или различий?

Автор: Станислав Гарматюк (nawhi@ixbt.com)
Выхода процессора Core i7, также известного под кодовым именем «Nehalem» ждали все. Ждали его и мы. Однако после того, как долгое ожидание закончилось, многие оказались, не побоимся этого слова, обескураженными: ведь ждали-то «простого и понятного» — что выпустит Intel первый свой процессор со встроенным контроллером памяти, а мы ей слегка попеняем за то, что она так долго не шла по давно проторенной AMD дорожке, но поглядим на результаты тестов производительности, умилимся, возрадуемся, и благодушно её простим. И вот, Intel выпустила Core i7. Однако оказалось, что это вовсе не «Core 2 со встроенным контроллером памяти», а нечто совсем-совсем другое. И как к этому относиться — совершенно непонятно. В этой, первой части статьи, посвящённой новой архитектуре Intel, мы попытаемся не прибегая к тестам понять, чего можно было ждать от нового процессора исключительно на основании описаний его характеристик. Ну а вторую часть, которая выйдет чуть позже, посвятим проверке сделанных нами предположений на практике.
Немного истории
Основной причиной для разработки ядра Nehalem послужило, разумеется, вовсе не желание Intel интегрировать в процессор контроллер памяти. Сам по себе встроенный контроллер памяти имело бы смысл использовать исключительно как средство повышения быстродействия — а повышать быстродействие своих процессоров ещё больше, Intel сейчас никаких резонов нет: основной конкурент и так отстал настолько безнадёжно, что вряд ли догонит в ближайшую пару лет. Таким образом, очевидно, что рассматривать Nehalem просто как «Core 2 со встроенным контроллером памяти» было бы серьёзной ошибкой, и это неправильное предположение, будучи сделанным в самом начале рассуждений, могло бы привести нас к совершенно неправильным выводам. В чём же на самом деле состоит смысл разработки нового ядра? Для этого нам придётся более пристально (и желательно «свежим», незамыленным взглядом) посмотреть на его предшественника — Core 2. Причём для полноты картины желательно не только с технической точки зрения, но и с исторической.
Какова была ситуация в Intel перед выходом Core 2? Или нет, давайте начнём даже раньше: какова была ситуация в Intel, когда Core 2 начали разрабатывать? Ситуация была, прямо скажем, напряжённая. Это, конечно, лишь предположение (однако вполне логичное), но о том, что архитектура NetBurst зашла в тупик, в Intel скорее всего знали задолго до того, как об этом узнали рядовые потребители или даже независимые тестовые лаборатории. Разумеется, отделы маркетинга и PR ещё могли некоторое время спасать ситуацию, однако всем было понятно, что время это вполне конечно. Поэтому, опять-таки, вполне логично будет предположить, что разрабатывалось ядро Conroe второпях*.
* — Даже первый образец Intel Pentium M (ядро Banias) разрабатывался, в общем-то, достаточно быстро. Но он разрабатывался как мобильный процессор. А вот когда израильское отделение Intel поставили перед задачей сделать из мобильного процессора настоящего десктопный процессор будущего, причём за очень сжатые сроки — вот тут-то началось настоящее веселье...
С другой стороны, учитывая количество времени, необходимое на разработку принципиально нового ядра (которое даже по идеологии сильно отличается от старого), и сравнивая по времени анонсы первых Pentium D и Athlon 64 X2 с анонсом первого процессора на архитектуре Core 2, мы можем сделать второе значимое предположение: вполне вероятно, на самом начальном этапе разработки, ядро Conroe вовсе не обязательно рассматривалось как база для создания на его основе многоядерных процессоров. Скорее всего, изначально разработчики приняли следующую стратегическую линию: «давайте сделаем хорошее одиночное исполнительное ядро, ну а если понадобиться сделать двухъядерник — что ж, слепим их вместе». В принципе, конструкция Conroe вполне подтверждает это предположение, и даже концепция разделяемого L2-кэша на него ложится, если хорошенько задуматься (забегая немного вперёд: обратите внимание — из Nehalem это промежуточное решение убрали, сделав разделяемым только L3). Более того: некоторые детали (например, работа технологии macrofusion) позволяют сделать крамольное предположение о том, что Conroe на начальном этапе разработки даже не был 64-битным! Но об этом позже…
Таким образом, мы наблюдаем в результате достаточно забавный технический парадокс: лучшие по производительности на данный момент времени двухъядерные и четырёхъядерные процессоры Intel Core 2 Duo / Core 2 Quad — по количеству «рудиментов» в архитектуре являются в некотором смысле намного более старыми, чем даже достаточно пожилой AMD Athlon 64 X2, и уж тем более Phenom X3/X4. Фактически, AMD и Intel подошли к решению задачи создания современного x86-64 CPU с разными акцентами: Intel как традиционалист сосредоточилась на разработке быстрого исполнительного ядра, а AMD как новатор привнесла даже в одноядерный Athlon 64 достаточно большое количество новинок, к которым так и просилась многоядерность (ну или хотя бы многопроцессорность). В этот раз чутьё Intel не подвело: лучшими многоядерными процессорами переходного периода оказались те, которые умеют быть хорошими одноядерными (так, например, анализ результатов некоторых тестов наводит на мысль о том, что едва ли не самая реально полезная «фишка» разделяемого L2-кэша Core 2 состоит в том, что при работе в «одноядерном режиме» почти весь L2-кэш отдаётся в распоряжение единственного занятого работой ядра). Впрочем, если задуматься о сути переходного периода — было бы странно, если бы случилось по-другому: ведь это именно то время, когда о поддержке многоядерности все производители ПО охотно говорят, но отнюдь не все торопятся что-то делать.
Однако переходный период подходит к концу, и перед инженерами R&D-отдела Intel встал вопрос: что делать дальше? Архитектура Core 2 — это очень сильное (по факту самое сильное из x86) исполнительное ядро, достаточно неплохо сбалансированные двухъядерники, уже намного более проблемные с архитектурной точки зрения четырёхъядерники, и… что дальше? А если аппетиты индустрии повысятся, и она будет готова с удовольствием «проглотить» и 8-ядерный процессор? Понятно, что у AMD есть определённые проблемы, и не в последнюю очередь технологические, поэтому вряд ли можно ожидать, что она успеет с 8-ядерным процессором раньше. Однако, с другой стороны, чисто архитектурно нынешний Phenom вполне готов к тому чтобы стать хоть 8-, хоть даже 16-ядерным. Core 2 оказался не совсем готов. Именно поэтому Intel нужно было новое ядро, или даже, скорее, новая архитектура — идеально масштабируемая, модульная, изначально созданная для конструирования на её основе многоядерных систем с достаточно большим количеством ядер (Intel употребляет термин «design-scalable microarchitecture»). Первым воплощением этой архитектуры стало ядро с кодовым наименованием Nehalem.
Основные черты новой архитектуры
Как уже было сказано выше, основной чертой новой архитектуры стала модульность. Главный модуль, если рассуждать с точки зрения не таких уж давних времён, представляет собой классический одноядерный x86-процессор: он состоит из исполнительного ядра, кэша 1-го уровня размером 64 КБ, поделенного на 2 равные части для данных и инструкций и кэша 2-го уровня размером 256 КБ. Уполовинить L1 — и чистой воды Pentium III Coppermine получится, вы не находите? :)
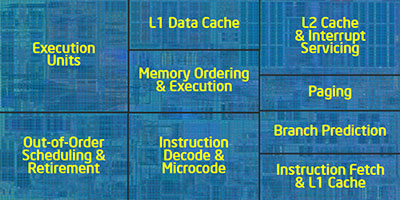
Прочие блоки могут быть следующими:
- разделяемый кэш 3-го уровня;
- контроллер памяти;
- контроллер шины QPI (QuickPath Interconnect);
- контроллер шины PCI Express (пока не реализовано);
- контроллер энергопотребления (PCU) и генератор частот;
- контроллер интегрированной графики (по некоторым данным, будет располагаться в одном корпусе с процессором, но на отдельном кристалле).
Впрочем, не думаем, что это строго фиксированный список, и ни одного пункта больше архитектура Core i7 включить не позволяет. Скорее данный набор базовых элементов является демонстрацией ближайших намерений Intel по дальнейшему усовершенствованию архитектуры — недаром в него вошёл контроллер интегрированной графики, на данный момент ни в одном процессоре Core i7 ещё не присутствующий. Всё это вместе может комбинироваться произвольным образом, причём допускается как наличие или отсутствие определённых модулей, так и различное их количество внутри процессора. Та модель, статья о тестировании которой выйдет чуть позже — Core i7 920 — выглядит, например, вот так:
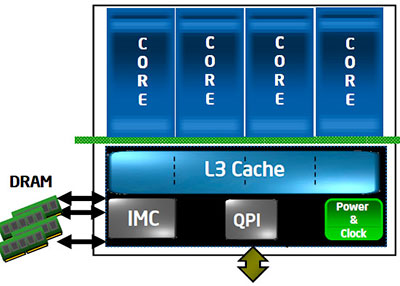
Как легко заметить, она включает в себя четыре процессорных ядра, один трёхканальный контроллер памяти DDR3, один контроллер шины QPI для общения с чипсетом, и модуль отвечающий за генерацию необходимых процессору для работы частот и управление энергопотреблением. С другой стороны, это лишь один из возможных вариантов, реализованный в данной конкретной модели. Например, если на базе новой архитектуры создавать серверный процессор — то не лишним будет увеличить количество не только ядер, но и контроллеров QPI, если же, наоборот, мы разрабатываем мобильный CPU — можно сократить количество ядер, чтобы уменьшить энергопотребление и заменить контроллер чересчур быстрой QPI на обычную PCI Express. Чисто теоретически, никто, наверное, не мешает убрать и L3, оставив всего по минимуму: одно исполнительное ядро, контроллер памяти, PCI-E (Celeron?..) Таким образом, главная цель Intel, похоже, достигнута: у неё есть модульная архитектура с достаточно небольшим количеством основных модулей, из которых, комбинируя их произвольным путём, можно достаточно легко «слепить» как скромный low-end процессор для какого-нибудь неттопа, так и многоядерного серверного монстра. И всё это — из одних и тех же модулей, вот в чём основная прелесть! Однако, разумеется, не только в модульности дело, есть и другие важные изменения. Давайте рассмотрим их подробнее.
Встроенный контроллер памяти
Разумеется, наиболее «очевидной» причиной для того, чтобы контроллер памяти в Nehalem был аж трёхканальным, многие назовут якобы нежелание Intel откровенно перенимать наработки AMD — дескать, нельзя же просто взять и сделать как у конкурента. Однако проанализировав внимательно мытарства самой AMD с её встроенным контроллером, начинаешь понимать, что в случае с Intel имели место отнюдь не эмоции или борьба за честь мундира, а наоборот — трезвый расчёт. Вспомните: AMD уже один раз пришлось переделывать контроллер памяти с DDR400 на DDR2-800 т.к. потребности некоторых приложений начали уже вплотную подходить к предельной ПСП. И это, разумеется, привело к переходу на другой сокет, другие системные платы, и прочим пертурбациям, весьма нервно воспринимаемым пользователями (особенно теми из них, кто рассчитывал на апгрейд). Заложив в конструкцию контроллера памяти Nehalem сразу три канала с поддержкой DDR3-1333 (серверные версии под кодовым наименованием Nehalem-EP) или DDR3-1066 (десктопные Nehalem), Intel скорее всего рассчитывает избавиться от необходимости кардинально переделывать данный узел хотя бы в ближайшие годы, или, по крайней мере, переделывать крайне незначительно. Например, добавление будущим CPU поддержки более высокочастотной DDR3 при желании можно реализовать таким образом, чтобы ради их установки не пришлось менять системную плату (ах, мечты, мечты…)
Что же касается самого контроллера, то нам, разумеется, обещают невиданную скорость прокачки данных (значение которой — 32 GBps — легко получить путём простого умножения максимальной ПС DDR3-1333 на количество каналов, поэтому сразу ясно, что речь идёт не о реальности, а о теоретическом максимуме), низкую латентность (почему бы и нет — контроллеры памяти в чипсетах Intel традиционно отличались низкой латентностью) и ещё некий «Aggressive Request Reordering». Судя по названию — самая, пожалуй, интересная деталь в новом контроллере, однако никаких существенных подробностей о работе данного механизма пока не раскрывается.
Технология Hyper-Threading (Simultaneous Multi-Threading)
По сути, мы вновь встречаем забытую было после закрытия ветки NetBurst-процессоров технологию Hyper-Threading, то есть эмуляцию нескольких логических ядер на базе одного физического. Даже иллюстрирующая суть процесса картинка как будто перескочила из старой презентации в новую (видимо, решили, что старую уже никто не помнит).
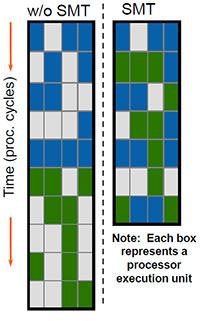
Как и в Pentium 4, остались у новой реинкарнации Hyper-Threading и некоторые «родовые болячки» старой, в частности, жёсткое разделение load/store/reorder буферов между двумя виртуальными ядрами пополам. Поэтому, в частности, вполне возможна ситуация, когда включение поддержки HT приведёт к снижению производительности (хотя справедливости ради стоит заметить, что на практике такое случается крайне редко). C другой стороны, по идее HT на Nehalem должна работать получше чем на Pentium 4 — не за счёт каких-то кардинальных улучшений в самой технологии, а просто потому, что у Nehalem некоторые ключевые для успешной работы данной технологии функциональные блоки существенно «шире», чем у Pentium 4 (об этом мы поговорим в следующих разделах).
Также время от времени встречается в сети информация, что Intel в Nehalem каким-то образом «разделила физические ядра и логические» и «сделала их неполноправными» с целью предоставить программистам возможность более тонко подстраиваться под особенности многопоточного программирования на процессорах с HT. Нам, честно говоря, трудно себе представить, как в принципе возможно осуществить такое разделение — ведь после включения HT все ядра становятся виртуальными, и первое эмулируемое на базе физического виртуальное ядро не может быть «более виртуально» или «менее виртуально», чем второе — иначе проблемы начнутся уже у любого программного обеспечения, которое ведёт себя «честно». Видимо, речь идёт просто о возможности каким-то способом определить (через фиксированно назначаемые номера CPU?..), исполняются ли некие нити (threads) процесса на виртуальных ядрах, относящихся к одному и тому же физическому процессору, или на виртуальных ядрах, относящихся к разным физическим (понятно, что вторая ситуация в общем случае более предпочтительна с точки зрения обеспечения максимального быстродействия конкретного процесса).
В целом же, поддержку Hyper-Threading на десктопных четырёхъядерниках сейчас следует воспринимать скорее как идеологический шаг, чем как заботу о большей эффективности использования ресурсов процессора: способностью эффективно использовать 8 (!) ядер из десктопного ПО обладает дай бог чтобы полпроцента, да и то это ПО настолько специфическое, что большинство рядовых пользователей запросто могут ни разу не столкнуться с ним на протяжении всей жизни.
Исполнительное ядро
Мы намеренно избегаем употребления термина «вычислительное ядро» т.к. «исполнительное» нам кажется более соответствующим фактическому положению вещей: в данном блоке происходят не только собственно вычисления, но и декодирование инструкций, да и в самом x86-коде отнюдь не все команды можно назвать термином «вычисления».
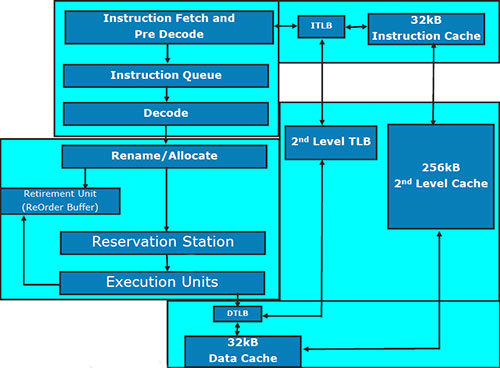
Большую часть изменений, внесенных в исполнительное ядро Core i7 по сравнению с Core 2, вкратце можно описать очень просто: «кое-где чуть-чуть добавили, кое-где чуть-чуть расширили». Подобного рода улучшения, как правило, и объясняются очень просто: новый технологический процесс позволил не экономить на транзисторах там, где раньше экономить приходилось. Далее мы вкратце опишем наиболее важные из внесенных изменений.
Декодер
Основные изменения в декодере связаны с дальнейшим усовершенствованием технологии macrofusion: раньше она работала только в 32-битном режиме, теперь же поддерживается во всех режимах работы процессора, в т.ч. в 64-битных, также увеличилось количество пар команд, декодируемых с помощью данной технологии за один такт. Теоретически, это должно привести к тому, что декодер Core i7 будет несколько чаще работать с полной отдачей (5 инструкций за такт), чем это происходило у Core 2.
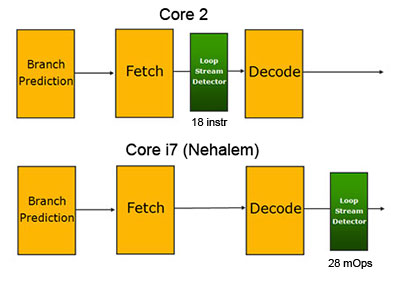
Обработка циклов
Специальный блок под названием Loop Stream Detector, предназначенный для сохранения коротеньких циклов с тем чтобы не загружать их заново из L1/L2, впервые появился в процессорах архитектуры Core 2. В Nehalem этот блок разместили после декодера, таким образом, он содержит уже декодированные команды. Идея явно взята из Pentium 4, там подобным образом был устроен весь кэш инструкций (Trace Cache).
Предсказание переходов
Блок предсказания переходов попросту удвоили: теперь он делится на две части, одна из которых работает над «быстрым» предсказанием переходов (эта часть, видимо, копирует соответствующий функциональный блок Core 2), вторая же работает медленнее, но за счёт более глубокого анализа и вместительного буфера позволяет предсказывать те переходы, на которых «быстрый» блок не срабатывает.
Также Intel обещает, что Return Stack Buffer (это блок, отвечающий за адреса возврата из функций) еще в Penryn был расширен функционально до Renamed RSB, и если ранее он иногда ошибался в случае использования сложных алгоритмов, то теперь в большинстве случаев ошибаться перестанет.
Исполнение инструкций
Блоки, отвечающие за исполнение инструкций, в Nehalem оставлены практически без изменений. Из чего, к слову, следует один простой, но не для всех очевидный вывод: в тех ситуациях, когда Core 2 и так успешно справляется с предвыборкой инструкций и данных, декодированием и предсказанием ветвлений — практически никакого преимущества все вышеперечисленные «навороты» Core i7 не дадут, и производительность его при равной с Core 2 частоте будет примерно такая же.
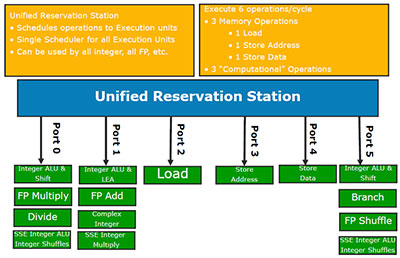
Однако некоторые изменения всё же были внесены, и связано это как раз с введением поддержки Hyper-Threading. Изменения, разумеется, самые что ни на есть очевидные: Reorder Buffer расширен до 128 микроопераций, Reservation Station — до 36 инструкций (было 32). Ну и буферы для данных, соответственно: Load с 32 до 48, Store — с 20 до 32. Для чего это нужно, также очевидно: чтобы увеличить количество команд и данных в очереди на исполнение, тем самым повысив вероятность того, что какие-то из них можно будет выполнить параллельно.
Новые инструкции (набор SSE4.2)
Поскольку мы уже выяснили выше, что в Nehalem Intel не предлагает нам никаких глобальных нововведений в исполняющих блоках, достаточно логичным выглядит и относительно скромное добавление к набору исполняемых инструкций: по отношению к анонсированному в Penryn набору SSE4.1, SSE4.2 содержит всего 7 новых инструкций, причём 2 из них метко названы самой Intel «Application Targeted Accelerators», т.е. инструкциями, ориентированными на ускорение не столько алгоритмов, сколько конкретных приложений. Одна из них — это инструкция для подсчёта 32-битной контрольной суммы (CRC32), призванная ускорить работу протокола iSCSI. Вторая инструкция подсчитывает количество ненулевых бит в операнде, и предназначена для программ генетической инженерии и распознавания голоса. Оставшиеся 5 инструкций имеют общее предназначение: все они призваны ускорить работу алгоритмов синтаксического анализа XML-файлов. Как видите, всё очень мирно и буднично, никаких сенсаций…
Подсистема кэширования
Тема удвоения при конструировании Nehalem была, видимо, очень актуальна: удвоили не только механизм предсказания ветвлений, но и TLB (Translation-Lookaside Buffer). Причём аналогичным предсказателю способом: оставив наследие Core 2 почти без изменений (лишь чуть увеличив размер), сверху над старым TLB водрузили новый, второго уровня — ещё большей вместимости (512 записей) и с расширенной функциональностью (TLB второго уровня может транслировать адреса страниц произвольного размера). Поддержка страниц произвольного размера десктопному процессору пригодится вряд ли, это специфика «тяжёлых», преимущественно серверных приложений, а вот большой TLB — это явно ещё один реверанс в сторону SMT.
Однако наибольшие изменения, естественно, коснулись «основной» подсистемы кэширования, а именно — взаимодействия между кэшами L1 и L2, а также появившимся у Nehalem L3. Во-первых, теперь снова L2 является «персональной собственностью» конкретного ядра, и оно ни с кем его не делит — разделяемым и общим для всех является кэш следующего уровня — L3. Во-вторых, Intel немного «переиграла» значения латентности для L1 и L2 — у L1 латентность стала на 1 такт больше, чем в Core 2, а у L2 она наоборот стала в полтора раза ниже.
Но основной интерес, конечно же, вызывает кэш 3-го уровня. Он, как и L2 в Core 2, является динамически разделяемым. Более того, он наконец-то является не «не-эксклюзивным», а именно инклюзивным: данные, находящиеся в L1/L2 — обязаны присутствовать в L3. Intel даже объясняет причину подобного решения (далее на рисунках левый соответствует эксклюзивному кэшу, а правый — инклюзивному).
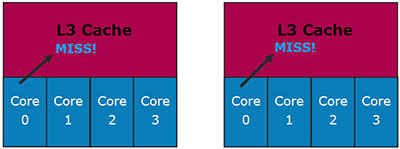
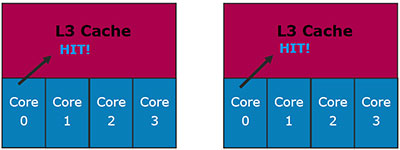
Рассмотрим первую ситуацию: ядро 0 запрашивает данные из L3-кэша, и они там не обнаруживаются.
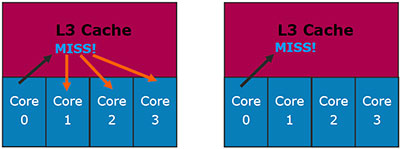
В случае с эксклюзивным кэшем (слева) это ещё ничего не значит: данные могут находится в L1/L2-кэшах других ядер. Инклюзивный кэш такую ситуацию исключает, поэтому никаких дополнительных проверок не требуется.
Рассмотрим другую ситуацию: ядро 0 запрашивает данные из L3-кэша, и они там обнаружены. В случае с эксклюзивным кэшем, проблем, наоборот, нет никаких: если данные обнаружены в L3 — то больше их нигде нет. В случае с инклюзивным кэшем могла бы возникнуть проблема: данные, наоборот, наверняка есть в L1/L2 одного из ядер. Которого?..
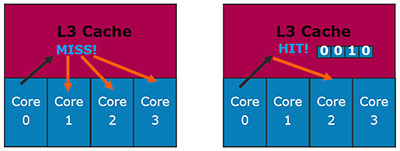
Для Nehalem эта проблема проблемой не является: каждая строка L3-кэша содержит биты core valid (по количеству физических ядер), которые указывают, копией содержимого L1/L2 какого ядра является данная строчка. Поэтому нет никакой необходимости опрашивать на предмет нахождения данных каждое ядро.
В общем, Intel придерживается достаточно последовательных взглядов в вопросе об оптимальной архитектуре кэша: лучше проиграть в объёме, чем в скорости. Быть может, это связано с тем, что у неё и так хорошо получается делать большие кэши? :) Некоторое разочарование вызывает тот факт, что L3 у Core i7 будет работать не на частоте процессора, а на некой фиксированной для целого ряда моделей частоте. Впрочем, эту ложку дёгтя насколько компенсируют два факта: во-первых, у AMD Phenom L3 тоже работает на фиксированной частоте, а во-вторых — у Core i7 эта частота выше (2,66 ГГц).
QPI как замена QPB
Мы, конечно, извиняемся за несколько неудобочитаемое название главы, но, право слово, очень уж напрашивался этот невинный каламбур: сокращённое наименование новой процессорной шины Intel (QuickPath Interconnect) ровно на одну букву отличается от сокращённого наименования старой (Quad Pumped Bus). Итак, что же представляет собой QPI? Технически, это двунаправленная 20-битная шина с топологией соединения «точка-точка», при этом 16 бит в каждую сторону несут полезную информацию, и ещё 4 бита служат для коррекции ошибок и прочих служебных целей. Работая со скоростью 6,4 миллиарда транзакций в секунду, QPI обеспечивает скорость передачи данных 12,8 ГБ/с в каждую сторону, и, соответственно, 25,6 ГБ/с в сумме, что позволяет ей претендовать на звание самой быстрой процессорной шины (1600 МГц QPB обеспечивает суммарную ПС 12,8 ГБ/с, AMD HyperTransport 3.0 — 24 ГБ/с). Впрочем, самым скоростным вариантом QPI пока планируется оснащать только Core i7 Extreme Edition, а на обычных Core i7 будет устанавливаться слегка замедленный вариант с пропускной способностью 4,8 миллиарда транзакций в секунду.
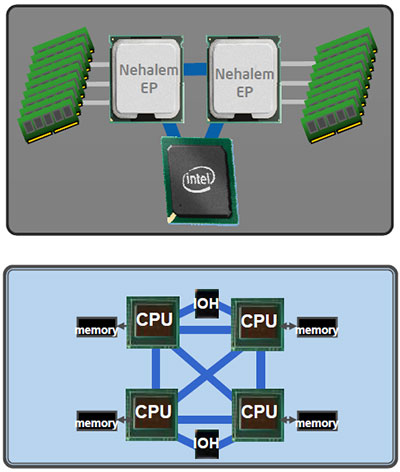
Разумеется, для десктопного процессора такая пропускная способность в подавляющем большинстве случаев избыточна, особенно учитывая тот факт, что QPI будет использоваться исключительно для связи с чипсетом — контроллер памяти уже встроен в процессор. (Актуальность данное решение имеет только для ситуации, когда чипсет обеспечивает большое количество линий PCI Express 2.0, как это реализовано в нынешнем чипсете для платформы Nehalem — Intel X58.) Поэтому совершенно очевидно, что разрабатывалась QPI для совершенно других применений, что вы и можете видеть на картинке выше. Процессоры на базе новой архитектуры, предназначенные для использования в серверном сегменте, будут содержать несколько контроллеров QPI, что позволит им быть связанными между собой напрямую «каждый с каждым» для оптимальной реализации архитектуры памяти Non-Uniform Memory Access (NUMA), которая, заметим, уже вовсю используется на серверных платформах ближайшего конкурента.
Таким образом, серверные варианты Core i7 и системы на их основе «топологически» станут очень похожими на AMD Opteron и системы на его основе — что, в целом, не может не радовать т.к. разработчики серверного ПО наконец-таки получат однозначный ответ на вопрос о том, под какую архитектуру памяти им оптимизировать свои приложения. Однако это всё, опять-таки, серверный сегмент, а на десктопе прелести QPI мало кто сможет почувствовать.
Управление энергопотреблением
Управлению энергопотреблением в Nehalem уделено такое количество внимания, что даже начинаешь всерьёз раздумывать, а не знала ли Intel загодя о всемирном экономическом кризисе. Причём подход был использован традиционно для новой архитектуры основательный и концептуальный: вся система управления энергопотреблением выделена в отдельный блок под названием PCU (Power Control Unit), который представляет собой фактически «процессор в процессоре», пусть и достаточно примитивный.
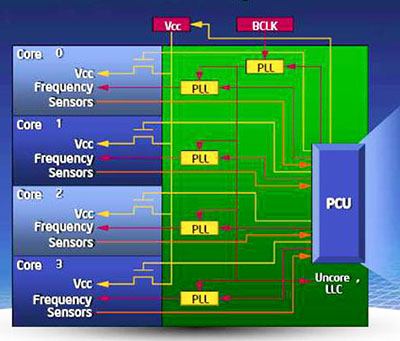
Этот управляемый собственной прошивкой микроконтроллер реализует намного более сложную схему управления питанием, чем в более старых процессорах Intel: частота и напряжение питания для каждого ядра регулируются отдельно на основании данных о его температуре и силе потребляемого тока. Таким образом, каждое ядро может быть переведено в состояние пониженного энергопотребления отдельно от других, а контроллеры памяти и шины QPI переводятся в состояние пониженного энергопотребления в случае когда все ядра находятся в незагруженном работой состоянии. По сути, примерно то же самое реализовала AMD в технологии Cool'n'Quiet 2.0 (Phenom), за одним только исключением: в C'n'Q 2.0 предусмотрена схема взаимодействия процессора с конвертором питания на системной плате, а управление энергопотреблением у Nehalem реализовано полностью внутри процессора и никаких дополнительных устройств не требует (и не предусматривает).
Технология Turbo Boost
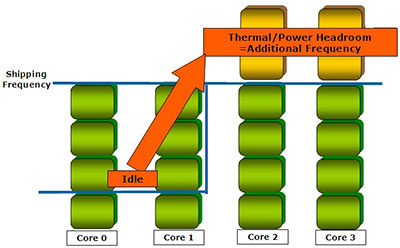
Intel шла к идее оверклокинга медленно, но верно: сначала оверклокерские функции появились в её платах, теперь вот — прямо в процессорах. :) Ну а если серьёзно, то именно наличие в составе Nehalem PCU, позволило реализовать ещё одну интересную особенность данного процессора: он может повышать частоту работы одного или нескольких ядер в том случае, если остальные простаивают. При этом, насколько нам удалось понять, доступны два варианта «турбирования» ядер: повышение частоты нескольких ядер на одну ступень (+133 МГц) и повышение частоты работы одного ядра на две ступени (+266 МГц). При этом подчёркивается, что совершенно не обязательно, чтобы остальные ядра были полностью разгружены: Turbo Mode включается в тех случаях, когда уровень загрузки ядер позволяет повысить частоту некоторых из них, не выходя за пределы максимального TDP. Дополнительным бонусом является то, что технология Turbo Boost, как и работа PCU — совершенно не связана ни с какой внешней поддержкой т.е. функционирует внутри процессора полностью самостоятельно и не требует задействования каких-либо дополнительных программных или аппаратных средств.
Заключение
Возвращаясь к сказанному в самом начале статьи, и продолжая прозвучавшие там мысли, можно подытожить наш беглый анализ новой архитектуры Intel следующими словами: если во времена стагнации NetBurst, Intel нужна была «архитектура-герой», которая вернула бы всему миру веру в то, что эта компания по-прежнему умеет делать хорошие и быстрые процессоры — то сейчас времена нужды в героизме давно уже пройдены, соответствующим образом изменились и приоритеты: теперь компания позвала на службу «архитектуру-бухгалтера» — предсказуемую, рачительную, склонную к систематизации и оптимизации всего и вся. Являясь по многим ключевым признакам преемницей предыдущей, новая выглядит намного более «отёсанной», приглаженной и отшлифованной. Всё-то тут правильно, логично и систематизировано, всё лежит на своих полочках, и сами полочки ширины и высоты ровно такой, какой нужно — и ни на миллиметр больше. Пожалуй, основная положительная черта новой архитектуры состоит в том, что такие процессоры будет очень легко разрабатывать и производить — она, можно сказать «производственно-ориентированная». К слову: как и всякий рачительный бухгалтер, у которого каждая копеечка на счету, новая архитектура бережно «подобрала» некоторые полезные находки вроде бы как признанных неперспективными предшественников — Hyper-Threading и Trace Cache из Pentium 4 / NetBurst. А чего зря валяются? В работу их, в работу!
И если смотреть на Nehalem именно с этой точки зрения — то сразу же отпадают вопросы о том, насколько он окажется быстрее Core 2. Да, наверное, на сколько-то окажется. Не медленнее же ему быть. Но суть-то вовсе не в этом. Суть в том, что мы наблюдаем Intel в самом начале пути, в конце которого в очередной раз находится весьма амбициозная цель: поставить на конвейер уже не только производство, но и самую разработку процессоров. А всё ведь очень просто: разбиваем процессор на «кубики», смотрим, в каком кубике по состоянию на сегодняшний день наблюдается наибольший «затык» — им и занимаемся. Устранили затык, вставили в старую конструкцию обновлённый кубик — вот вам и новый процессор, дорогие потребители, ещё краше предыдущего (в котором другой кубик совершенствовали). И так до бесконечности. Можно, в конце концов, даже набор инструкций сменить, если припрёт — ведь теперь им занимается всего лишь один из стандартных кубиков. Почему-то нам кажется, что в этот раз Intel всё удастся. Хотя, собственно, отчего «почему-то»? Известно, почему: потому что подобный вариант развития событий в долгосрочной перспективе всех устраивает: и саму Intel, и сборщиков, и конечных потребителей. Скучновато, конечно, будет — ну да ничего, потерпим…
Итак, чего же всё-таки больше между Core 2 и Core i7 — сходства или различий? Мы бы сказали, что сходства и различия лежат несколько в разных плоскостях. Nehalem унаследовал от Conroe/Penryn важную часть микроархитектуры (собственно — исполнительное ядро), но по архитектуре он отличается от Core 2 разительно: сразу видно, что этот процессор разрабатывался для решения совсем других задач и для достижения намного более далёких горизонтов, чем просто выигрыш в гонке производительности. Пусть это прозвучит даже несколько дерзко по отношению к очень неплохой линейке процессоров Core 2 — но, тем не менее, мы осмелимся предположить, что её стратегическая задача как раз в том и состояла, чтобы Intel получила возможность не отвлекаться на всякие мелочи вроде соперничества за первое место по скорости, а тихо и спокойно доработать новую долгоиграющую концепцию развития своих процессоров, первым практическим воплощением которой стала линейка процессоров Core i7.
Опубликовано — 8 декабря 2008 г.

