| |
Etc.: Структуризированный язык запросов (SQL)
Содержание
Глава 1. Реляционные базы данных и язык SQLРеляционная база данных представляется пользователю как совокупность таблиц и ничего кроме таблиц. На рис.1.1 приведен пример реляционной базы данных ПАНСИОН. Этот простой пример используется для иллюстрации большинства вопросов, рассматриваемых в нашей книге. Поэтому советуем потратить немного времени, чтобы хорошо с ним разобраться*. Кладовая пансионата периодически пополняется продуктами из списка, часть которого показана в таблице Продукты. Каждый продукт имеет кроме названия (столбец Продукт) уникальный номер этого продукта (столбец ПР). Химический состав продуктов приведен для 1 кг их съедобной части: основные пищевые вещества (белки, жиры и углеводы) даны в граммах, а минеральные вещества (калий, кальций, натрий) и витамины (B2, PP, C) - в миллиграммах. В таблице Блюда представлены уникальные номера блюд (столбец БЛ), их названия, коды видов (см. таблицу Вид_блюд), основной продукт (столбец Основа), масса порции в граммах (столбец Выход) и приведенная стоимость в копейках приготовления одной порции (столбец Труд). В таблице Рецепты приведена технология приготовления блюд. Их выделение в отдельную таблицу произведено потому, что одно и то же блюдо может иметь несколько разных рецептов. Таблица Состав связывает между собой таблицы Блюда и Продукты, оговаривая, какая масса (в граммах) того или иного продукта (столбец Вес) должна входить в состав одной порции блюда. Так, порция блюда с номером 12 (Суп молочный) должна состоять из 350 г продукта с номером 7 (Молоко), 35 г продукта с номером 13 (Рис), 5 г продукта с номером 3 (Масло) и 5 г продукта с номером 16 (Сахар). Шеф-повар ежедневно получает от завхоза сведения о количестве в килограммах имеющихся продуктов и их текущей стоимости (столбцы К_во и Стоимость таблицы Наличие). Используя эти сведения он определяет по таблице Состав перечень тех блюд, которые можно приготовить из этих продуктов, а также калорийность и стоимость таких блюд. При этом стоимость блюда складывается из стоимости и массы продуктов, необходимых для приготовления одной его порции, а также из трудозатрат на ее приготовление (см. таблицу Блюда). Калорийность же определяется по массе и калорийности каждого из продуктов блюда. (Для получения значения калорийности продукта исходят из того, что при окислении 1 г углеводов или белков в организме освобождается в среднем 4.1 ккал, а при окислении 1 г жиров - 9.3 ккал.) | Блюда | Рецепты |
|---|
| БЛ | Блюдо | В | Основа | Выход | Труд |
|---|
| 1 | Салат летний | З | Овощи | 200. | 3 | | 2 | Салат мясной | З | Мясо | 200. | 4 | | 3 | Салат витаминный | З | Овощи | 200. | 4 | | 4 | Салат рыбный | З | Рыба | 200. | 4 | | 5 | Паштет из рыбы | З | Рыба | 120. | 5 | | 6 | Мясо с гарниром | З | Мясо | 250. | 3 | | 7 | Сметана | З | Молоко | 140. | 1 | | 8 | Творог | З | Молоко | 140. | 2 | | 9 | Суп харчо | С | Мясо | 500. | 5 | | 10 | Суп-пюре из рыбы | С | Рыба | 500. | 6 | | 11 | Уха из судака | С | Рыба | 500. | 5 | | 12 | Суп молочный | С | Молоко | 500. | 3 | | 13 | Бастурма | Г | Мясо | 300. | 5 | | 14 | Бефстроганов | Г | Мясо | 210. | 6 | | 15 | Судак по-польски | Г | Рыба | 160. | 5 | | 16 | Драчена | Г | Яйца | 180. | 4 | | 17 | Морковь с рисом | Г | Овощи | 260. | 3 | | 18 | Сырники | Г | Молоко | 220. | 4 | | 19 | Омлет с луком | Г | Яйца | 200. | 5 | | 20 | Каша рисовая | Г | Крупа | 210. | 4 | | 21 | Пудинг рисовый | Г | Крупа | 160. | 6 | | 22 | Вареники ленивые | Г | Молоко | 220. | 4 | | 23 | Помидоры с луком | Г | Овощи | 260. | 4 | | 24 | Суфле из творога | Г | Молоко | 280. | 6 | | 25 | Рулет с яблоками | Д | Фрукты | 200. | 5 | | 26 | Яблоки печеные | Д | Фрукты | 160. | 3 | | 27 | Суфле яблочное | Д | Фрукты | 220. | 6 | | 28 | Крем творожный | Д | Молоко | 160. | 4 | | 29 | "Утро" | Н | Фрукты | 200. | 5 | | 30 | Компот | Н | Фрукты | 200. | 2 | | 31 | Молочный напиток | Н | Молоко | 200. | 2 | | 32 | Кофе черный | Н | Кофе | 200. | 1 | | 33 | Кофе на молоке | Н | Кофе | 200. | 2 |
| | БЛ | Рецепт |
|---|
| 1 | Помидоры ... | | 2 | Вареное ... | | 3 | Зелень ме... | | 4 | Вареные р... | | 5 | Филе суда... | | 6 | Мясо варе... | | 7 | Сметану п... | | 8 | Протертый .. | | 9 | Грудинку ... | | 10 | Филе суда... | | 11 | Судак очи... | | 12 | Промытый ... | | 13 | Мясо наре... | | 14 | Говядину ... | | 15 | Подготовл... | | 16 | Сырые яйц... | | 17 | Нарезать ... | | 18 | В протерт... | | 19 | К свежим ... | | 20 | Рис свари... | | 21 | Готовую р... | | 22 | В протерт... | | 23 | Спассеров... | | 24 | В протерт... | | 25 | Очистить ... | | 26 | Не прорез... | | 27 | Запеченны... | | 28 | Яйца разм... | | 29 | Очищенную .. | | 30 | Яблоки оч... | | 31 | Яблоки на... | | 32 | Кофеварку .. | | 33 | Сварить ч... |
|
| Поставщики |
|---|
| ПС | Название | Статус | Город | Адрес | Телефон | | 1 | СЫТНЫЙ | рынок | Ленинград | Сытнинская, 3 | 2329916 | | 2 | ПОРТОС | кооператив | Резекне | Садовая, 27 | 317664 | | 3 | ШУШАРЫ | совхоз | Пушкин | Новая, 17 | 4705038 | | 4 | ТУЛЬСКИЙ | универсам | Ленинград | Тульская, 3 | 2710837 | | 5 | УРОЖАЙ | коопторг | Луга | Песчаная, 19 | 789000 | | 6 | ЛЕТО | агрофирма | Ленинград | Пулковское ш.,8 | 2939729 | | 7 | ОГУРЕЧИК | ферма | Паневежис | Укмерге, 15 | 127331 | | 8 | КОРЮШКА | кооператив | Йыхви | Нарвское ш., 64 | 432123 |
|
| Состав | Поставки |
|---|
| БЛ | ПР | Вес | БЛ | ПР | Вес | БЛ | ПР | Вес | БЛ | ПР | Вес |
|---|
| 1 | 11 | 100 | 9 | 11 | 25 | 16 | 7 | 35 | 24 | 8 | 80 | | 1 | 15 | 80 | 9 | 13 | 35 | 16 | 6 | 15 | 24 | 7 | 100 | | 1 | 12 | 5 | 9 | 12 | 15 | 16 | 14 | 9 | 24 | 5 | 40 | | 1 | 4 | 15 | 9 | 3 | 15 | 16 | 3 | 5 | 24 | 6 | 30 | | 2 | 1 | 65 | 10 | 2 | 70 | 17 | 9 | 150 | 24 | 16 | 20 | | 2 | 9 | 40 | 10 | 7 | 250 | 17 | 7 | 50 | 24 | 3 | 10 | | 2 | 11 | 35 | 10 | 3 | 20 | 17 | 13 | 25 | 24 | 14 | 10 | | 2 | 12 | 20 | 10 | 14 | 15 | 17 | 3 | 20 | 25 | 15 | 120 | | 2 | 5 | 20 | 10 | 12 | 5 | 17 | 12 | 10 | 25 | 16 | 35 | | 2 | 4 | 20 | 11 | 2 | 100 | 17 | 14 | 5 | 25 | 14 | 30 | | 3 | 11 | 55 | 11 | 9 | 20 | 18 | 8 | 140 | 25 | 8 | 20 | | 3 | 15 | 55 | 11 | 10 | 20 | 18 | 6 | 30 | 25 | 3 | 20 | | 3 | 6 | 50 | 11 | 3 | 5 | 18 | 14 | 15 | 26 | 15 | 150 | | 3 | 12 | 20 | 11 | 12 | 2 | 18 | 5 | 10 | 26 | 16 | 20 | | 3 | 10 | 15 | 12 | 7 | 350 | 18 | 16 | 15 | 26 | 3 | 2 | | 3 | 16 | 5 | 12 | 13 | 35 | 19 | 5 | 120 | 27 | 15 | 50 | | 4 | 2 | 50 | 12 | 3 | 5 | 19 | 7 | 45 | 27 | 7 | 150 | | 4 | 11 | 50 | 12 | 16 | 5 | 19 | 10 | 20 | 27 | 5 | 80 | | 4 | 4 | 40 | 13 | 1 | 180 | 19 | 3 | 15 | 27 | 16 | 35 | | 4 | 9 | 35 | 13 | 11 | 100 | 20 | 13 | 50 | 27 | 3 | 2 | | 4 | 5 | 20 | 13 | 10 | 40 | 20 | 7 | 75 | 28 | 8 | 100 | | 4 | 12 | 5 | 13 | 12 | 20 | 20 | 15 | 75 | 28 | 5 | 20 | | 5 | 2 | 80 | 13 | 3 | 5 | 20 | 16 | 10 | 28 | 6 | 20 | | 5 | 9 | 40 | 14 | 1 | 90 | 20 | 3 | 5 | 28 | 16 | 15 | | 5 | 3 | 25 | 14 | 7 | 50 | 21 | 13 | 70 | 28 | 3 | 10 | | 5 | 12 | 5 | 14 | 6 | 20 | 21 | 6 | 30 | 29 | 15 | 150 | | 6 | 1 | 80 | 14 | 10 | 10 | 21 | 3 | 20 | 29 | 9 | 200 | | 6 | 11 | 150 | 14 | 3 | 5 | 21 | 5 | 20 | 29 | 16 | 15 | | 6 | 4 | 30 | 14 | 12 | 5 | 21 | 16 | 15 | 30 | 15 | 70 | | 6 | 12 | 10 | 14 | 14 | 3 | 22 | 8 | 140 | 30 | 16 | 10 | | 7 | 6 | 125 | 15 | 2 | 100 | 22 | 6 | 30 | 31 | 7 | 150 | | 7 | 16 | 15 | 15 | 9 | 20 | 22 | 14 | 20 | 31 | 15 | 150 | | 8 | 8 | 75 | 15 | 5 | 20 | 22 | 16 | 15 | 31 | 16 | 25 | | 8 | 6 | 50 | 15 | 3 | 20 | 22 | 5 | 8 | 32 | 17 | 8 | | 8 | 16 | 15 | 15 | 10 | 10 | 23 | 11 | 250 | 33 | 17 | 8 | | 9 | 1 | 80 | 15 | 12 | 5 | 23 | 10 | 65 | 33 | 16 | 25 | | 9 | 10 | 30 | 16 | 5 | 120 | 23 | 3 | 20 | 33 | 7 | 75 |
| | ПС | ПР | Цена | К_во |
|---|
| 1 | 9 | | 1 | 11 | 1.50 | 50 | | 1 | 12 | 3.00 | 10 | | 1 | 15 | 2.00 | 170 | | 2 | 1 | 3.60 | 300 | | 2 | 3 | | 2 | 5 | 1.80 | 100 | | 2 | 6 | 3.60 | 80 | | 2 | 8 | | 3 | 7 | 0.40 | 200 | | 3 | 9 | | 3 | 12 | 2.50 | 20 | | 3 | 15 | 1.50 | 200 | | 4 | 2 | | 4 | 4 | 2.04 | 50 | | 4 | 13 | 0.88 | 150 | | 4 | 14 | | 4 | 16 | 0.94 | 200 | | 4 | 17 | 4.50 | 50 | | 5 | 4 | 3.00 | 50 | | 5 | 9 | | 5 | 10 | 0.50 | 130 | | 5 | 11 | | 5 | 13 | 1.20 | 40 | | 5 | 14 | 0.50 | 70 | | 5 | 16 | 1.00 | 50 | | 6 | 10 | 0.70 | 90 | | 6 | 11 | | 6 | 12 | | 7 | 1 | 4.20 | 70 | | 7 | 3 | 4.00 | 250 | | 7 | 6 | 2.20 | 140 | | 7 | 7 | | 7 | 8 | 1.00 | 150 | | 8 | 2 | | 8 | 5 | 2.00 | 70 | | 8 | 11 | 1.00 | 100 |
|
| Продукты | Наличие |
|---|
| ПР | Продукт | Белки | Жиры | Углев | K | Ca | Na | B2 | PP | C |
|---|
| 1 | Говядина | 189. | 124. | 0. | 3150 | 90 | 600 | 1.5 | 28. | 0 | | 2 | Судак | 190. | 80. | 0. | 1870 | 270 | 0 | 1.1 | 10. | 30 | | 3 | Масло | 60. | 825. | 90. | 230 | 220 | 740 | 0.1 | 1. | 0 | | 4 | Майонез | 31. | 670. | 26. | 480 | 280 | 0 | 0. | 0. | 0 | | 5 | Яйца | 127. | 115. | 7. | 1530 | 550 | 710 | 4.4 | 1.9 | 0 | | 6 | Сметана | 26. | 300. | 28. | 950 | 850 | 320 | 1. | 1. | 2 | | 7 | Молоко | 28. | 32. | 47. | 1460 | 1210 | 1500 | 1.3 | 1. | 10 | | 8 | Творог | 167. | 90. | 13. | 1120 | 1640 | 1410 | 2.7 | 4. | 5 | | 9 | Морковь | 13. | 1. | 70. | 2000 | 510 | 210 | 0.7 | 9.9 | 50 | | 10 | Лук | 17. | 0. | 95. | 1750 | 310 | 180 | 0.2 | 2. | 100 | | 11 | Помидоры | 6. | 0. | 42. | 290 | 140 | 400 | 0.4 | 5.3 | 250 | | 12 | Зелень | 9. | 0. | 20. | 340 | 275 | 75 | 1.2 | 4. | 380 | | 13 | Рис | 70. | 6. | 773. | 540 | 240 | 260 | 0.4 | 16. | 0 | | 14 | Мука | 106. | 13. | 732. | 1760 | 240 | 120 | 1.2 | 22. | 0 | | 15 | Яблоки | 4. | 0. | 113. | 2480 | 160 | 260 | 0.3 | 3. | 130 | | 16 | Сахар | 0. | 0. | 998. | 30 | 20 | 10 | 0. | 0. | 0 | | 17 | Кофе | 127. | 36. | 9. | 9710 | 180 | 180 | 0.3 | 1.8 | 0 |
| | ПР | К_во | Стоим |
|---|
| 1 | 108 | 429.84 | | 2 | 0 | 0.00 | | 3 | 73 | 274.61 | | 4 | 39 | 97.46 | | 5 | 61 | 111.83 | | 6 | 88 | 206.60 | | 7 | 214 | 83.08 | | 8 | 92 | 82.80 | | 9 | 0 | 0.00 | | 10 | 77 | 46.30 | | 11 | 46 | 51.70 | | 12 | 13 | 34.96 | | 13 | 54 | 51.14 | | 14 | 91 | 43.77 | | 15 | 117 | 189.92 | | 16 | 98 | 96.14 | | 17 | 37 | 166.50 |
|
| Вид_блюд | Трапезы | Меню | Выбор | Выбрано |
|---|
| В | Вид |
|---|
| З | Закуска | | С | Суп | | Г | Горячее | | Д | Десерт | | Н | Напиток |
| | Т | Трапеза |
|---|
| 1 | Завтрак | | 2 | Обед | | 3 | Ужин |
| | Т | В | БЛ | Т | В | БЛ | Т | В | БЛ |
|---|
| 1 | З | 3 | 2 | З | 1 | 3 | З | 6 | | 1 | З | 6 | 2 | З | 6 | 3 | З | 8 | | 1 | Г | 19 | 2 | С | 9 | 3 | Г | 20 | | 1 | Г | 21 | 2 | С | 12 | 3 | Г | 16 | | 1 | Н | 31 | 2 | Г | 14 | 3 | Н | 30 | | 1 | Н | 32 | 2 | Г | 16 | 3 | Н | 31 | | 2 | Г | 18 | | | 2 | Д | 26 | | | 2 | Д | 28 | |
| | СМ | Т | В | БЛ |
|---|
| 2 | 1 | З | 3 | | 2 | 1 | Г | 19 | | 2 | 1 | Н | 31 | | 2 | 2 | З | 1 | | 2 | 2 | С | 12 | | 2 | 2 | Г | 16 | | 2 | 2 | Д | 26 | | 2 | 3 | З | 8 | | 2 | 3 | Г | 21 | | 2 | 3 | Н | 32 |
| | СМ | Т | БЛ |
|---|
| 1 | 1 | 3 | | 1 | 1 | 21 | | . |
|---|
| 2 | 2 | 16 | | 2 | 2 | 26 | | . |
|---|
| 3 | 1 | 6 | | . |
|---|
| 32 | 3 | 30 |
|
Рис. 1.1. Основные таблицы базы данных ПАНСИОН Учитывая примерную стоимость и необходимую калорийность дневного рациона отдыхающих, шеф-повар составляет меню на следующий день. В этом меню (таблица Меню) предлагается по несколько альтернативных блюд каждого вида (таблица Вид_блюд) и для каждой трапезы (таблица Трапезы). Перед завтраком каждый отдыхающий вводит в ЭВМ номер закрепленного за ним места в столовой пансионата (столбец СМ в таблице Выбор) и желаемый набор блюд для каждой из трапез следующего дня (в примере таблица заполнялась отдыхающим, сидящим на месте с номером 2). Таблицы Выбор объединяются по мере их создания в общую таблицу Выбрано, по которой определяют, сколько порций того или иного блюда надо приготовить для каждой трапезы. Завхоз связан с поставщиками продуктов, сведения о которых хранятся в таблице Поставщики. Эта таблица содержит уникальный номер поставщика (столбец ПС), его название, статус, месторасположение и телефон. Таблица Поставки связывает между собой таблицы Продукты и Поставщики, оговаривая, какое количество продукта (столбец К_во) и по какой цене поставил тот или иной поставщик. Отсутствие в строке цены и количества говорит о том, что поставщик ПС может поставлять продукт ПР, но в данный момент не осуществил такой поставки. Легко заметить, что все таблицы примера (как и все таблицы любой реляционной базы данных) состоят из строки заголовков столбцов и одной или более строк значений данных под этими заголовками. Эти столбцы и строки должны иметь следующие свойства: - всякому столбцу таблицы присвоено имя, которое должно быть уникальным для этой таблицы;
- столбцы таблицы упорядочиваются слева направо, т.е. столбец 1, столбец 2, ..., столбец n. С математической точки зрения это утверждение некорректно, потому что в реляционной системе столбцы не упорядочены. Однако с точки зрения пользователя, порядок, в котором определены имена столбцов, становится порядком, в котором должны вводиться в них данные, если не предварять при вводе каждое значение именем соответствующего столбца (подробнее это описано в Приложении А литературы [2]);
- строки таблицы не упорядочены (их последовательность определяется лишь последовательностью ввода в таблицу);
- в поле на пересечении строки и столбца любой таблицы всегда имеется только одно значение данных и никогда не должно быть множества значений (правда, это "атомарное" значение может быть достаточно объемным, например, таким, как рецепт блюда);
- всем строкам таблицы соответствует одно и то же множество столбцов, хотя в определенных столбцах любая строка может содержать пустые значения (NULL-значения), т.е. может не иметь значений для этих столбцов;
- все строки таблицы обязательно отличаются друг от друга хотя бы единственным значением, что позволяет однозначно идентифицировать любую строку такой таблицы;
- при выполнении операций с таблицей ее строки и столбцы можно обрабатывать в любом порядке безотносительно к их информационному содержанию.
Почему же база данных, составленная из таких таблиц, называется реляционной? А потому, что отношение - relation - просто математический термин для обозначения неупорядоченной совокупности однотипных записей или таблиц определенного специфического вида, описанного выше. Таким образом, можно, например, сказать, что база данных ПАНСИОН состоит из одиннадцати отношений. Реляционные системы берут свое начало в математической теории множеств. Они были предложены в конце 1968 года доктором Э.Ф.Коддом из фирмы IBM, который первым осознал, что можно использовать математику для придания надежной основы и строгости области управления базами данных. Нечеткость многих терминов, используемых в сфере обработки данных, заставила Кодда отказаться от них и придумать новые или дать более точные определения существующим. Так, он не мог использовать широко распространенный термин "запись", который в различных ситуациях может означать экземпляр записи, либо тип записей, запись в стиле Кобола (которая допускает повторяющиеся группы) или плоскую запись (которая их не допускает), логическую запись или физическую запись, хранимую запись или виртуальную запись и т.д. Вместо этого он использовал термин "кортеж длины n" или просто "кортеж", которому дал точное определение. В литературе [2,3] можно подробно познакомиться с терминологией реляционных баз данных, а здесь мы будем использовать неформальные их эквиваленты: | таблица | для отношения, | | строка или запись | для кортежа, | | столбец или поле | для атрибута. |
Мы также принимаем, по определению, что "запись" означает "экземпляр записи", а "поле" означает "имя и тип поля". * Так как иллюстративная база данных создавалась для лекционного курса в 1988 году, когда существовали "смешные" цены, а также исчезнувшие названия статусов (коопторг) и городов (Ленинград), то автор пытался несколько раз ее модифицировать. Однако поняв, что изменение цен, статусов и названий идет быстрее, чем подготовка и, тем более, выпуск издания, он решил сохранить в книге старые цены и названия. ^^^ Все языки манипулирования данными (ЯМД), созданные до появления реляционных баз данных и разработанные для многих систем управления базами данных (СУБД) персональных компьютеров, были ориентированы на операции с данными, представленными в виде логических записей файлов. Это требовало от пользователей детального знания организации хранения данных и достаточных усилий для указания не только того, какие данные нужны, но и того, где они размещены и как шаг за шагом получить их. Рассматриваемый же ниже непроцедурный язык SQL (Structured Query Language - структуризованный язык запросов) ориентирован на операции с данными, представленными в виде логически взаимосвязанных совокупностей таблиц. Особенность предложений этого языка состоит в том, что они ориентированы в большей степени на конечный результат обработки данных, чем на процедуру этой обработки. SQL сам определяет, где находятся данные, какие индексы и даже наиболее эффективные последовательности операций следует использовать для их получения: не надо указывать эти детали в запросе к базе данных. Для иллюстрации различий между ЯМД рассмотрим следующую ситуацию. Пусть, например, вы собираетесь посмотреть кинофильм и хотите воспользоваться для поездки в кинотеатр услугами такси. Одному шоферу такси достаточно сказать название фильма - и он сам найдет вам кинотеатр, в котором показывают нужный фильм. (Подобным же образом, самостоятельно, отыскивает запрошенные данные SQL.) Для другого шофера такси вам, возможно, потребуется самому узнать, где демонстрируется нужный фильм и назвать кинотеатр. Тогда водитель должен найти адрес этого кинотеатра. Может случиться и так, что вам придется самому узнать адрес кинотеатра и предложить водителю проехать к нему по таким-то и таким-то улицам. В самом худшем случае вам, может быть, даже придется по дороге давать указания: "Повернуть налево... проехать пять кварталов... повернуть направо...". (Аналогично больший или меньший уровень детализации запроса приходится создавать пользователю в разных СУБД, не имеющих языка SQL.) Появление теории реляционных баз данных и предложенного Коддом языка запросов "alpha", основанного на реляционном исчислении [2, 3], инициировало разработку ряда языков запросов, которые можно отнести к двум классам: - Алгебраические языки, позволяющие выражать запросы средствами специализированных операторов, применяемых к отношениям (JOIN - соединить, INTERSECT - пересечь, SUBTRACT - вычесть и т.д.).
- Языки исчисления предикатов представляют собой набор правил для записи выражения, определяющего новое отношение из заданной совокупности существующих отношений. Другими словами исчисление предикатов есть метод определения того отношения, которое нам желательно получить (как ответ на запроc) из отношений, уже имеющихся в базе данных.
Разработка, в основном, шла в отделениях фирмы IBM (языки ISBL, SQL, QBE) и университетах США (PIQUE, QUEL) [3]. Последний создавался для СУБД INGRES (Interactive Graphics and Retrieval System), которая была разработана в начале 70-х годов в Университете шт. Калифорния и сегодня входит в пятерку лучших профессиональных СУБД. Сегодня из всех этих языков полностью сохранились и развиваются QBE (Query-By-Example - запрос по образцу) и SQL, а из остальных взяты в расширение внутренних языков СУБД только наиболее интересные конструкции. В начале 80-х годов SQL "победил" другие языки запросов и стал фактическим стандартом таких языков для профессиональных реляционных СУБД. В 1987 году он стал международным стандартом языка баз данных и начал внедряться во все распро-страненные СУБД персональных компьютеров. Почему же это произошло? Непрерывный рост быстродействия, а также снижение энергопотребления, размеров и стоимости компьютеров привели к резкому расширению возможных рынков их сбыта, круга пользователей, разнообразия типов и цен. Естественно, что расширился спрос на разнообразное программное обеспечение. Борясь за покупателя, фирмы, производящие программное обеспечение, стали выпускать на рынок все более и более интеллектуальные и, следовательно, объемные программные комплексы. Приобретая (желая приобрести) такие комплексы, многие организации и отдельные пользователи часто не могли разместить их на собственных ЭВМ, однако не хотели и отказываться от нового сервиса. Для обмена информацией и ее обобществления были созданы сети ЭВМ, где обобществляемые программы и данные стали размещать на специальных обслуживающих устройствах - файловых серверах. СУБД, работающие с файловыми серверами, позволяют множеству пользователей разных ЭВМ (иногда расположенных достаточно далеко друг от друга) получать доступ к одним и тем же базам данных. При этом упрощается разработка различных автоматизированных систем управления организациями, учебных комплексов, информационных и других систем, где множество сотрудников (учащихся) должны использовать общие данные и обмениваться создаваемыми в процессе работы (обучения). Однако при такой идеологии вся обработка запросов из программ или с терминалов пользовательских ЭВМ выполняется на этих же ЭВМ. Поэтому для реализации даже простого запроса ЭВМ часто должна считывать из файлового сервера и (или) записывать на сервер целые файлы, что ведет к конфликтным ситуациям и перегрузке сети. Для исключения указанных и некоторых других недостатков была предложена технология "Клиент-Сервер", по которой запросы пользовательских ЭВМ (Клиент) обрабатываются на специальных серверах баз данных (Сервер), а на ЭВМ возвращаются лишь результаты обработки запроса. При этом, естественно, нужен единый язык общения с Сервером и в качестве такого языка выбран SQL. Поэтому все современные версии профессиональных реляционных СУБД (DB2, Oracle, Ingres, Informix, Sybase, Progress, Rdb) и даже нереляционных СУБД (например, Adabas) используют технологию "Клиент-Сервер" и язык SQL. К тому же приходят разработчики СУБД персональных ЭВМ, многие из которых уже сегодня снабжены языком SQL. Бытует мнение: Поскольку большая часть запросов формулируется на SQL, практически безразлично, что это за СУБД - был бы SQL. Реализация в SQL концепции операций, ориентированных на табличное представление данных, позволило создать компактный язык с небольшим (менее 30) набором предложений. SQL может использоваться как интерактивный (для выполнения запросов) и как встроенный (для построения прикладных программ). В нем существуют: - предложения определения данных (определение баз данных, а также определение и уничтожение таблиц и индексов);
- запросы на выбор данных (предложение SELECT);
- предложения модификации данных (добавление, удаление и изменение данных);
- предложения управления данными (предоставление и отмена привилегий на доступ к данным, управление транзакциями и другие). Кроме того, он предоставляет возможность выполнять в этих предложениях:
- арифметические вычисления (включая разнообразные функциональные преобразования), обработку текстовых строк и выполнение операций сравнения значений арифметических выражений и текстов;
- упорядочение строк и (или) столбцов при выводе содержимого таблиц на печать или экран дисплея;
- создание представлений (виртуальных таблиц), позволяющих пользователям иметь свой взгляд на данные без увеличения их объема в базе данных;
- запоминание выводимого по запросу содержимого таблицы, нескольких таблиц или представления в другой таблице (реляционная операция присваивания).
- агрегатирование данных: группирование данных и применение к этим группам таких операций, как среднее, сумма, максимум, минимум, число элементов и т.п.
В SQL используются следующие основные типы данных, форматы которых могут несколько различаться для разных СУБД: - INTEGER
- - целое число (обычно до 10 значащих цифр и знак);
- SMALLINT
- - "короткое целое" (обычно до 5 значащих цифр и знак);
- DECIMAL(p,q)
- - десятичное число, имеющее p цифр (0 < p < 16) и знак; с помощью q задается число цифр справа от десятичной точки (q < p, если q = 0, оно может быть опущено);
- FLOAT
- - вещественное число с 15 значащими цифрами и целочисленным порядком, определяемым типом СУБД;
- CHAR(n)
- - символьная строка фиксированной длины из n символов (0 < n < 256);
- VARCHAR(n)
- - символьная строка переменной длины, не превышающей n символов (n > 0 и разное в разных СУБД, но не меньше 4096);
- DATE
- - дата в формате, определяемом специальной командой (по умолчанию mm/dd/yy); поля даты могут содержать только реальные даты, начинающиеся за несколько тысячелетий до н.э. и ограниченные пятым-десятым тысячелетием н.э.;
- TIME
- - время в формате, определяемом специальной командой, (по умолчанию hh.mm.ss);
- DATETIME
- - комбинация даты и времени;
- MONEY
- - деньги в формате, определяющем символ денежной единицы ($, руб, ...) и его расположение (суффикс или префикс), точность дробной части и условие для показа денежного значения.
В некоторых СУБД еще существует тип данных LOGICAL, DOUBLE и ряд других. СУБД INGRES предоставляет пользователю возможность самостоятельного определения новых типов данных, например, плоскостные или пространственные координаты, единицы различных метрик, пяти- или шестидневные недели (рабочая неделя, где сразу после пятницы или субботы следует понедельник), дроби, графика, большие целые числа (что стало очень актуальным для российских банков) и т.п. Ориентированный на работу с таблицами SQL не имеет достаточных средств для создания сложных прикладных программ. Поэтому в разных СУБД он либо используется вместе с языками программирования высокого уровня (например, такими как Си или Паскаль), либо включен в состав команд специально разработанного языка СУБД (язык систем dBASE, R:BASE и т.п.). Унификация полных языков современных профессиональных СУБД достигается за счет внедрения объектно-ориентированного языка четвертого поколения 4GL. Последний позволяет организовывать циклы, условные предложения, меню, экранные формы, сложные запросы к базам данных с интерфейсом, ориентированным как на алфавитно-цифровые терминалы, так и на оконный графический интерфейс (X-Windows, MS-Windows). ^^^ До сих пор понятие "таблица", как правило, связывалось с реальной или базовой таблицей, т.е. c таблицей, для каждой строки которой в действительности имеется некоторый двойник, хранящийся в физической памяти машины (рис.1.2). Однако SQL использует и создает ряд виртуальных (как будто существующих) таблиц: представлений, курсоров и неименованных рабочих таблиц, в которых формируются результаты запросов на получение данных из базовых таблиц и, возможно, представлений. Это таблицы, которые не существуют в базе данных, но как бы существуют с точки зрения пользователя. Базовые таблицы создаются с помощью предложения CREATE TABLE (создать таблицу), подробное описание которого приведено в главе 5. Здесь же приведем пример предложения для создания описания таблицы Блюда: 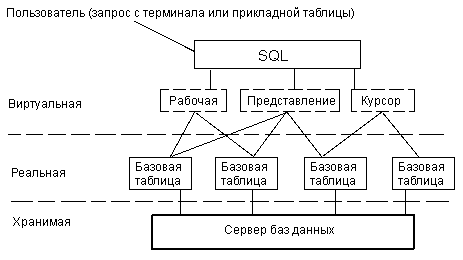
Рис. 1.2. База данных в восприятии пользователя
CREATE TABLE Блюда
(БЛ SMALLINT,
Блюдо CHAR (70),
В CHAR (1),
Основа CHAR (10),
Выход FLOAT,
Труд SMALLINT);
Предложение CREAT TABLE специфицирует имя базовой таблицы, которая должна быть создана, имена ее столбцов и типы данных для этих столбцов (а также, возможно, некоторую дополнительную информацию, не иллюстрируемую данным примером). CREAT TABLE - выполняемое предложение. Если его ввести с терминала, система тотчас построит таблицу Блюда, которая сначала будет пустой: она будет содержать только строку заголовков столбцов, но не будет еще содержать никаких строк с данными. Однако можно немедленно приступить к вставке таких строк данных, возможно, с помощью предложения INSERT и создать таблицу, аналогичную таблице Блюда рис.1.1. Если теперь потребовалось узнать какие овощные блюда может приготовить повар пансионата, то можно набрать на терминале следующий текст запроса:
SELECT БЛ,Блюдо
FROM Блюда
WHERE Основа = 'Овощи'; и мгновенно получить на экране следующий результат его реализации: | БЛ | Блюдо |
|---|
| 1 | Салат летний | | 3 | Салат витаминный | | 17 | Морковь с рисом | | 23 | Помидоры с луком |
Для выполнения этого предложения SELECT (выбрать), подробное описание которого будет дано в главах 2 и 3, СУБД должна сначала сформировать пустую рабочую таблицу, состоящую из столбцов БЛ и Блюдо, тип данных которых должен совпадать с типом данных аналогичных столбцов базовой таблицы Блюда. Затем она должна выбрать из таблицы Блюда все строки, у которых в столбце Основа хранится слово Овощи, выделить из этих строк столбцы БЛ и Блюдо и загрузить укороченные строки в рабочую таблицу. Наконец, СУБД должна выполнить процедуры по организации вывода содержимого рабочей таблицы на экран терминала (при этом если в рабочей таблице содержится более 20-24 строк, она должна использовать процедуры постраничного вывода и т.п.). После выполнения запроса СУБД должна уничтожить рабочую таблицу. Если, например, надо получить значение калорийности всех овощей, включенных в таблицу Продукты, то можно набрать на терминале запрос
SELECT Продукт, Белки, Жиры, Углев,
((Белки+Углев)*4.1+Жиры*9.3)
FROM Продукты
WHERE Продукт IN ('Морковь','Лук','Помидоры','Зелень');и получить на экране следующий результат его реализации: | Продукт | Белки | Жиры | Углев | ((Белки+Углев)*4.1+Жиры*9.3) |
|---|
| Морковь | 13. | 1. | 70. | 349.6 | | Лук | 17. | 0. | 95. | 459.2 | | Помидоры | 6. | 0. | 42. | 196.8 | | Зелень | 9. | 0. | 20. | 118.9 |
В последнем столбце этой рабочей таблицы приведены данные о калорийности продуктов, отсутствующие в явном виде в базовой таблице Продукты. Эти данные вычислены по хранимым значениям основных питательных веществ продуктов, помещены в рабочую таблицу и будут существовать до момента смены изображения на экране. Однако если необходимо сохранить эти данные в какой-либо базовой таблице, то существует предложение (INSERT), позволяющее переписать содержимое рабочей таблицы в указанные столбцы базовой таблицы (реляционная операция присваивания). Часто пользователя не устраивает как способ описания нужного набора выводимых строк, так и результат выполнения запроса, сформированного из данных одной таблицы. Ему хотелось бы уточнить выводимые (запрашиваемые) данные сведениями из других таблиц. Например, в запросе на получение состава овощных блюд
SELECT БЛ,ПР,Вес
FROM Состав
WHERE БЛ IN (1,3,17,23); пришлось перечислять номера этих блюд, так как в таблице Состав нет данных об основных продуктах блюда (они есть в таблице Блюда). Полученный состав овощных блюд (рис.1.3,а) оказался "слепым": в нем и блюда и продукты представлены номерами, а не именами. Удобнее и нагляднее (рис.1.3,б) | а) | б) | | БЛ | ПР | Вес | Блюдо |
|---|
| 1 | 11 | 100 | Салат летний | | 1 | 15 | 80 | Салат летний | | 1 | 12 | 5 | Салат летний | | 1 | 4 | 15 | Салат летний | | 3 | 11 | 55 | Салат витаминный | | 3 | 15 | 55 | Салат витаминный | | 3 | 6 | 50 | Салат витаминный | | 3 | 12 | 20 | Салат витаминный | | 3 | 10 | 15 | Салат витаминный | | 3 | 16 | 5 | Салат витаминный | | 17 | 9 | 150 | Морковь с рисом | | 17 | 7 | 50 | Морковь с рисом | | 17 | 13 | 25 | Морковь с рисом | | 17 | 3 | 20 | Морковь с рисом | | 17 | 12 | 10 | Морковь с рисом | | 17 | 14 | 5 | Морковь с рисом | | 23 | 11 | 250 | Помидоры с луком | | 23 | 10 | 65 | Помидоры с луком | | 23 | 3 | 20 | Помидоры с луком |
| | Продукт | Вес |
|---|
| Помидоры | 100 | | Яблоки | 80 | | Зелень | 5 | | Майонез | 15 | | Помидоры | 55 | | Яблоки | 55 | | Сметана | 50 | | Зелень | 20 | | Лук | 15 | | Сахар | 5 | | Морковь | 150 | | Молоко | 50 | | Рис | 25 | | Масло | 20 | | Зелень | 10 | | Мука | 5 | | Помидоры | 250 | | Лук | 65 | | Масло | 20 |
|
Рис. 1.3. Состав овощных блюд базы данных ПАНСИОН запрос сформированный по трем таблицам: SELECT Блюдо, Продукт, Вес
FROM Состав,Б люда, Продукты
WHERE Состав.БЛ = Блюда.БЛ
AND Состав.ПР = Продукты.ПР
AND Основа = 'Овощи'; В нем для получения рабочей таблицы выполняется естественное соединение [2] таблиц Блюда, Продукты и Состав (условие соединения - равенство значений номеров блюд и значений номеров продуктов). Затем выделяются строки, у которых в столбце Основа хранится слово Овощи, и из этих строк - столбцы Блюдо, Продукт и Вес. Если пользователи достаточно часто интересуются составом различных блюд, то для упрощения формирования запросов целесообразно создать представление. Представление - это пустая именованная таблица, определяемая перечнем тех столбцов таблиц и признаками тех их строк, которые хотелось бы в ней увидеть. Представление является как бы "окном" в одну или несколько базовых таблиц. Оно создается с помощью предложения CREATE VIEW (создать представление), подробное описание которого приведено в главе 5. Здесь же приведем пример предложения для создания представления Состав_блюд:
CREATE VIEW Состав_блюд
AS SELECT Блюдо, Продукт, Вес
FROM Состав,Блюда,Продукты
WHERE Состав.БЛ = Блюда.БЛ
AND Состав.ПР = Продукты.ПР; Оно описывает пустую таблицу, в которую при реализации запроса будут загружаться данные из столбцов Блюдо, Продукт и Вес таблиц Блюда, Продукты и Состав, соответственно. Теперь для получения состава овощных блюд можно дать запрос
SELECT Блюдо,Продукт,Вес
FROM Состав_блюд
WHERE Основа = 'Овощи'; и получить на экране терминала данные, которые представлены на рис. 1.3,б. А для получения состава супа Харчо можно дать запрос
SELECT Блюдо, Продукт, Вес
FROM Состав_блюд
WHERE Блюдо = 'Суп харчо'; О целесообразности создания представлений будет рассказано ниже, а здесь лишь отметим, что они позволяют повысить уровень логической независимости данных, упростить их восприятие и "скрыть" от некоторых пользователей те или иные данные, например, данные о новых ценах на продукты первой необходимости или из какой рыбы приготавливается "Судак по-польски". Наконец, еще об одних виртуальных таблицах - курсорах. Курсор - это пустая именованная таблица, определяемая перечнем тех столбцов базовых таблиц и признаками тех их строк, которые хотелось бы в ней увидеть. В чем же различие между курсором и представлением? Для пользователя представления почти не отличаются от базовых таблиц (есть лишь некоторые ограничения при выполнении различных операций манипулирования данными). Они могут использоваться как в интерактивном режиме, так и в прикладных программах. Курсоры же созданы для процедурной работы с таблицей в прикладных программах. Например, после объявления курсора
DECLARE Блюд_состав CURSOR FOR
SELECT Блюдо,Продукт,Вес
FROM Состав,Блюда,Продукты
WHERE Состав.БЛ = Блюда.БЛ
AND Состав.ПР = Продукты.ПР
AND Блюдо = 'Суп харчо'; и его активизации (OPEN Блюд_состав) будет создана временная таблица с составом блюда "Суп харчо" и специальным указателем, определяющим в качестве текущей первую строку этой таблицы. С помощью предложения FETCH (выбрать), которое обычно исполняется в программном цикле, можно присвоить определенным переменным значения указанных столбцов этой строки. Одновременно курсор будет передвинут к следующей строке таблицы. После обработки в программе полученных значений переменных выполняется следующее предложение FETCH и т.д. до окончания перебора всех продуктов Харчо. ^^^
Далее >>>
|

